[Paper Notes] Facebook Haystack and F4
前言
Haystack 和 F4 是 Facebook 为了解决照片存储的场景开发的一套小文件存储系统。整个设计非常简洁(褒义,虽然简洁到让人怀疑这也能发 OSDI),但是却把每个部分的设计和考虑解释得非常清楚。读完 GFS 会感觉有不少未解之谜在 paper 中没交代清楚,但读完 Haystack 和 F4 就感觉异常通顺。Facebook 一开始开发了 Haystack 是为了覆盖整个照片存储场景,后来发现了温存储场景可以优化的地方,又开发了 F4 将冷数据从 Haystack 中剥离出来,单独存储,并且 F4 的 paper 中描述了整套 BLOB Storage 系统同时修改了一些 Haystack 的设定,因此将这两篇放在一起讲。F4 也分享了很多 Facebook 在这套系统的设计和使用上的很多经验,值得学习。
Haystack
Needle in a haystack
Needle 是 Haystack 中的基本存储单位,英文翻译是针,Haystack 的英文翻译是草垛。出于好奇 Facebook 为什么取了这个名字的目的去搜了一下,发现这是一句类似于“大海捞针”(草垛里捞针)的常用短语,这么理解的话这个名字对于一个存储海量小文件的存储系统就非常形象了~
场景
在开发 Haystack 之前,Facebook 使用基于 NFS 的设计方案。每个小文件直接对应 NFS 上的一个物理文件,在 CDN Cache Miss 的文件会直接通过 Photo Server 落到 NFS 上读,这种方案的缺陷非常明显,就是小文件给文件系统带来的太多元数据。POSIX 文件系统在文件节点上存储了大量 Facebook 的场景下不需要的信息(如权限信息等),每个 INode 都要占据大约 500 byte 的空间,导致在大量小文件的场景下,文件系统无法将元信息全部缓存到自己的内存中,访问数据的时候,除了必须要的一次数据读取的磁盘 IO,在获取元数据以定位真实数据位置的过程中也需要经过若干次磁盘 IO,这是基于 NFS 的系统导致图片访问慢的主要原因。
Haystack 的优化目标非常明确,就是砍掉无用的元信息,压缩元信息到足够小并全部加载到内存中,将对单张图片的访问精确地缩减为一次磁盘 IO。
Haystack 的优化思路也非常的简单,既然小文件的元信息太多,那么就把大量小文件打包成大文件再存,自己维护小文件需要的少量 元信息。在 Haystack 中,存储的小文件及其元信息称为 Needle,而打成的大文件包称为 Volume。Haystack 的核心部分其实就是这个单机的小文件存储引擎。
架构
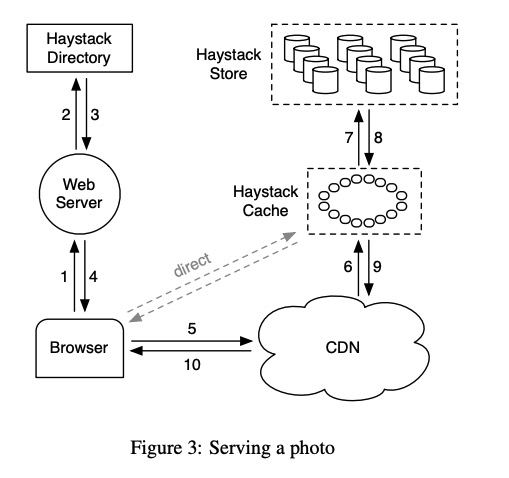
Haystack Cache
Facebook 的架构里用户除了访问 CDN 以外,也可以跳过 CDN 直接访问数据,这两种请求最终都会由 Haystack Cache 处理(猜测区别仅仅是内部和外部 Cache)。Haystack Cache 就是个很平凡的 Cache 逻辑,以 Photo ID 为 key 维护了一个分布式哈希表,如果请求的照片没有缓存,就从底层的 Haystack Store 读取数据,并且对满足一定条件的查询结果进行缓存。
这块唯一需要注意一些的就是这个缓存条件,当且仅当满足两个条件的时候,Haystack Cache 才会进行缓存:
- 直接来自用户,而非来自 CDN 的请求。对于一般的来自 CDN 的请求,Haystack 直接将缓存的任务交给对方。从这个角度来看,Haystack Cache 的定位基本就等于一个系统内部的 CDN。
- 照片存在 write-enabled 节点上的。这个跟之后提到的照片热度的 Timezone 有关,可以简单理解为从 Facebook 的场景来看,上传了很长一段时间以后的照片没有缓存价值。
Haystack Store
Haystack Store 是最核心的模块,也就是 Haystack 的存储节点。Haystack 放弃了原生的 POSIX 作为小文件存储的接口,但沿用了 POSIX 文件系统的底层,自己基于这个底层开发了一个单机的小文件存储系统,并运行在每块 Disk 或者每个节点上、
每个 Volume 有唯一的 Volume ID,标识一个 Logical Volume,但为了数据可靠性,每个 Logical Volume 在集群内会有三个副本,这些 Volume 实体称为 Physical Volume,在单机的存储引擎中。这些 Physical Volume 是真实的 POSIX 文件系统下的文件单位,分散在 Haystack Store 的节点中。
每个 Volume 会存储数百万张照片,并由三个文件组成,Data file 和 Index file 和 Journal file(后续加入)。Data file 由连续的 Needle 组成,每个 Needle 除了存储图片本身的数据以外,还存储了一些额外的元信息,其中比较 重要的有照片的 key 和 alternate key,图片的 size 和 checksum,以及一个删除标志位。
key 和 alternate key 用于 Facebook 场景下的二层索引,因为 Facebook 对每张照片存了四种不同 size 的图片(包括缩略图,小图,大图,原图),因此每张照片有一个主键,然后再通过 alternate key 对应到需要的尺寸的图片。
根据 key 和 alternate key,Haystack store 的每个节点在内存中为每个 volume 构建了一个双层的索引,用于快速找到对应的 Needle 在 data file 中的偏移量,并缓存了 size 信息减少一次读取元信息的 IO。而 Index file 是这个索引文件的一个快照。
一个 Volume 支持数据粒度的 Read,Write 和 Delete 操作,实现在了解数据的定义之后都非常的 trivial,直接通过下面的伪代码展示,但有一些场景需要考虑。
Index file 是定期 dump 到磁盘中的,因此宕机时会丢失数据,需要恢复,对于新写入的数据这非常简单,因为遗失的数据总是在 data file 的尾部,从 index 中最高的 offset 开始从 data file 恢复这些 meta 信息即可。但是对于删除的数据无法简单地恢复,在旧版本的 Haystack(即 Haystack paper)中,删除是通过修改 data file 中 needle 的标志位来完成持久化的,而在新版本(F4 paper 中提到的 Haystack),每次删除文件仅需要在 journal file 中添加一条记录,这是磁盘 append 操作因此非常快,而 Index 在宕机恢复时仅需要将 Journal file 和 Index file 做一个 merge 即可。
1 | |
为了避免垃圾数据过多,volume 还会根据一定条件触发 Compaction,回收已经被 Delete 或者被 Write 覆盖的数据。
除了单个 volume,我们考虑一下如何在多个 Physical volume 之间保持一致性,Haystack 的答案似乎就是根本不管。由于 Write 和 Delete 非常幂等,并且 Photo Store 稍微不一致也不是特别要紧,Haystack 选择添加监控并且手动处理一些不一致的异常情况。
Haystack Directory
这是个 paper 笔墨很少,但十分重要的组件,它存储了所有的元信息,比如 volume ID 到 physical volume 位置的映射。它负责调度用户的请求,包括负载均衡写请求的 logical volume,负载均衡读请求打到哪个 physical volume 等的调度。为了避免一个 volume 无限增长造成运维困难,directory 会在 volume 大小达到一定容量时将 volume 标记为 read-only。
Pitchfork
这个就是个健康检测后台任务,定期给所有存储节点发请求,观测到一个 volume 发生异常时标记为 read-only 并找运维人肉处理。这不会影响服务的整体可用性,因为写请求可以打到任意一个 volume。
F4
F4 是 Facebook 在 Haystack 之后又搞的一个 Warm blob store,这个 warm 就比较魔性,让人想起星巴克的中杯、大杯和超大杯。不过事实上,F4 存储的确实不是冷存储,而是 Facebook 的一些 long tail 的照片,他们仍然会被获取,但是频率较低,也很少被覆盖或删除。相比于一些获取数据需要以天为单位的真正的 cold storage,F4 仍然要求对数据的获取在百毫秒级的时间内完成响应。
F4 和 Haystack 的关系
在 Haystack 中的数据因为三副本的原因有比较高的存储成本,F4 的设计目标主要是在保证数据安全的情况下降低数据的存储成本。一点可以利用的性质是从 Haystack 导入 F4 的照片很少会被删除,我们可以认为整个 Volume 都是不可变数据。
Haystack 和 F4 的接口完全保证一致,通过 router tier 对用户隐藏具体实现。
在数据导入的时间点上,Haystack 基于底层硬件设备(HDD)的读写能力和 BLOB 的使用情况统计进行设计,以 80 IOPS/TB 作为分界线对统计结果进行划分,并确定了三个月的分界线,即对于 Facebook 的大部分 BLOB 数据来说,在经过三个月的时间以后,访问频率就会降到显著低于 80 IOPS/TB,以至于使用廉价的 HDD 作为存储介质依然可以提供不影响用户体验的服务。这个设计过程也是充分地利用了软硬件一体的设计思想。
设计
为了减少空间的使用,F4 引入了 EC(erasure coding)的技术。n:m 的 EC 可以将一份数据切为 n 份,并且构造 m 个冗余块。在这 (n+m) 个块中任意丢失 m 块数据,都能通过剩下 n 个块恢复。因此保障数据安全仅需要 (n+m)/n 的空间。Facebook 选择了 10:4 的比例,比起三副本来说,可以节约大量的空间。为了异地灾备,Facebook 在两个不同的集群之间再次通过对两个 Volume XOR 编码,并将这份冗余块备份到第三个集群中,通过 1.4 * 1.5 = 2.1 倍的空间完成了异地灾备级别的数据可靠性。
在 F4 中,一个从 Haystack 导入的 Volume 前会经过 compaction。在 F4 中,Volume 里较小的 index file 仍然通过三副本,但是占 Volume 主体的 data file 完全通过 EC 来保障数据的可靠性和可用性。每个 data file 会按固定的大小(1GB 左右)切成连续的 data block,然后为每 n 个 data block(称为 strip),生成 m 个 parity block,不足 n 个的部分填零补全。每个 Strip 对应的 n+m 个 block 会被分布在不同的机架中,来保证机架级别的容错域。
架构
架构上分为了五种类型的节点,并将这些节点打包成了一个 F4 Cell。
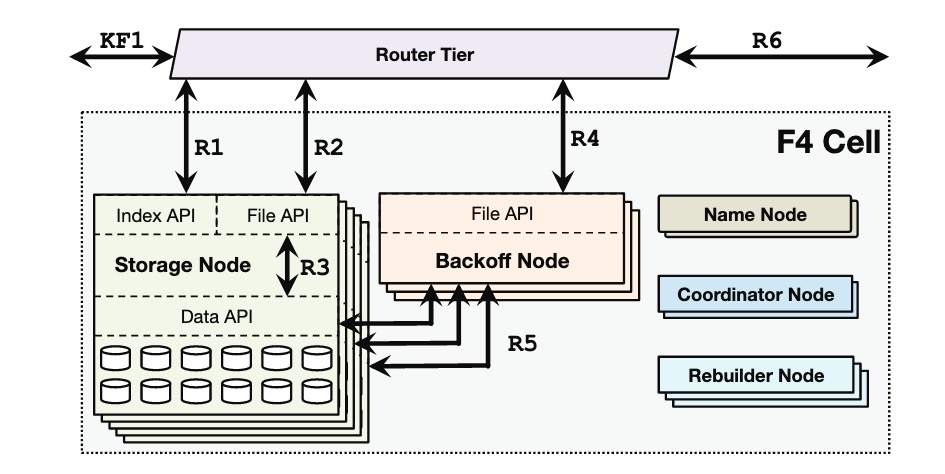
- Name Node:管理了 Volume -> Strip -> Block 的 Mapping 关系的 NameNode,这个功能非常简单直接忽略其实现。
- Storage Node:Storage Heavy 的节点,应该配有大量的 HDD,存储 Block,并管理对 Block 的读取操作。
- Backoff Node:CPU Heavy 的节点,在部分 data blocks 损坏时,在 parity blocks 继续读取数据对外提供服务保证可用性。
- Rebuilder Node:在有 data block 或者 parity block 损坏时,负责恢复数据。由于 F4 paper 中没有提到 Volume 如何从 Haystack 中入库到 F4 中,猜测初始化 parity block 这部分也是由 Rebuilder Node 负责。
- Coordinator Node:一个 Cell 的任务调度节点。进行一些定期检查,容错域调度等维护任务的调度。
Others
删除
虽然 F4 不支持修改数据,但为了用户数据的隐私,允许对数据进行删除。
在最开始的设计中,F4 的开发者计划在 F4 中保留 Haystack 中的 Jornal file 作为文件的删除记录,并保留 compaction 的策略。很快他们发现在 F4 设计中留这个可变的因素会大大增加设计复杂度。因此 F4 换了个删除的思路,将所有 BLOB 在导入 F4 前用每个 BLOB 唯一的秘钥加密,并将秘钥存在外部数据库中,如果需要删除数据,只需要在外部数据库中删除这个秘钥,就能让加密的 BLOB 无法通过任何手段恢复原来的数据,从逻辑上做到了 BLOB 的删除。
effective-replication-factor
这个词翻不太来,大约是指备份的数据相比原始数据的比例。在 Haystack 中这个数字是 3.6,由三备份和 1.2 倍的 RAID 组成,在 F4 中,这个数字被降低到了 2.1。不过这个可以节约空间的前提是建立在 F4 中的数据删除比例比较少,根据 Facebook 的统计结果,对于大于三个月的 BLOB,这个结论成立。