pubfnget<'cache>(&'cachemutself, k: &K) ->Option<&'cache V> { // SAFETY: We actually hold `&'cache mut self` here, so the only reference should always be valid. // We can extend its lifetime to the cache easily. self.scope(|mut cache, perm| unsafe { std::mem::transmute::<_, Option<&'cache V>>(cache.get(k, &perm)) }) } }
我们可以像正常的 collection API 一样来使用它:
1 2 3 4 5 6
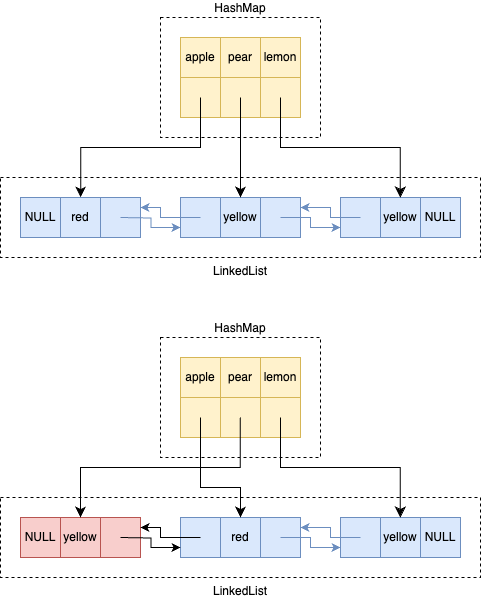
letmut cache = LruCache::new(2); cache.put("apple", "red", &mut perm); letdata = cache.get("apple"); // We can't call `get` twice when `data` reference is still valid. // cache.get("lemon"); dbg!(data);
我添加了一大堆 UI Test,来覆盖各种使用场景和应该编译失败的场景,感兴趣的朋友可以看一下这些 test case。
Conclusion
上一篇文章的末尾,我们提到了这套 API 较差的易用性可能限制了它的应用空间,那么这篇文章的改进在我看来,如果可以证明其 soundness,甚至达到了可以合并到标准库的程度(我会尝试给标准库的 LinkedList、VecDeque 等提 Reference Stability 的 RFC)。这个将数据和操作分离的 API 改进,我们只需要在原本的数据结构上单独添加一个 scope API,并且在对应的 closure 内遵循权限分离的设计。而在不需要 reference stability 的场景,我们不会引入任何额外的代码复杂度,真正地做到了 “pay as you needed”,这非常符合 Rust 的设计哲学。
]]><p>在<a href="https://blog.zhuangty.com/ref-stable-lru/">上一篇文章</a>中,我们设计了一个允许同时持有多个不可变引用的 <code>LruCache</code>。唯一的问题是,为了足够安全,API 不太易用。这篇文章完美Design a collection with compile-time reference stability in Rust (1)https://blog.zhuangty.com/ref-stable-lru/2024-01-26T19:03:00.000Z2024-06-10T13:19:55.919ZLRU Cache 是工业界最常用的数据结构之一,而最简单的实现方式是基于 HashMap 和链表。当访问某个 entry 时,这个 entry 会被移到链表的最前端。
可以看到,与常规数据结构不同的是,这里的 get 方法,也需要接受 &mut self,这给使用者带来很多困扰。例如我们可能希望同时持有多个 V 的不可变引用,这可以允许我们减少不必要的 copy,或者并发地使用他们。
1 2 3 4
letx = cache.get(&"a").unwrap().as_str(); lety = cache.get(&"b").unwrap().as_str(); letz = cache.get(&"c").unwrap().as_str(); [x, y, z].join(" ");
我们会得到如下报错:
1 2 3 4 5 6 7 8 9
error[E0499]: cannot borrow `cache` as mutable more than once at a time | 20 | let x = cache.get(&"a").unwrap().as_str(); | ----- first mutable borrow occurs here 21 | let y = cache.get(&"b").unwrap().as_str(); 22 | let z = cache.get(&"c").unwrap().as_str(); | ^^^^^ second mutable borrow occurs here 23 | [x, y, z].join(" "); | - first borrow later used here
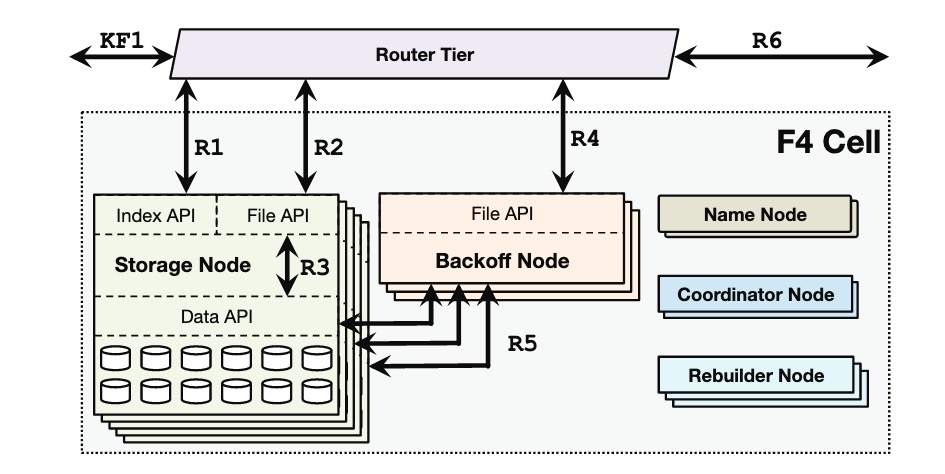
3 是本文想介绍的重点。简单来说,RisingWave 既不是一个 local state backend,也不是 remote state backend,而是一个混合形态。只有最新的 barrier 之后的 state 才是算子自身维护的 local state,而之前的数据则是 remote state。当且仅当收到 barrier 的时候,算子才会选择 dump 状态到 hummock store。这也就是 hummock store 只提供 ingest batch 接口的原因 ———— 算子只会在收到 barrier 的时候将 local state dump 到 hummock 中去。
Async Checkpoint
前文中我们提到,算子在收到 barrier 时,会选择 dump 数据到 Hummock,但我们也提到了 barrier 是随着数据流一起流动的,如果每个算子都需要同步地将等待状态被上传到 shared storage(目前是 S3),那么数据处理就会 blocking 一整个上传的 Round trip。如果 DAG 中有 N 个有状态算子的话,那么 barrier 在整个传递过程中就会被 delay N 个 round trip,这对整个系统的处理能力会产生很大的影响。因此,我们将 barrier 的处理流程几乎全异步化了。有状态算子在收到 barrier 后需要做的唯一一件事,就是将当前 epoch 的 local state 同步地 std::mem::take 走,重置为一个空的 state,让算子可以接着处理下一个 epoch 的数据。这也引入了一系列的问题:
这个 epoch 的 local state 被 take 到哪里去了?
既然 local state 并没有同步地上传到 S3,那么针对这段时间数据的查询应该怎么处理呢?
在异步上传的时候,算子 crash 了怎么办,如何知道 checkpoint 是否成功?
为了解答上面的这些问题,我们引入了 Shared Buffer。
Shared Buffer
Shared Buffer 是一个 Compute Node 的所有算子共享的一个后台任务,当有状态算子收到 barrier 之后,local state 会被 take 到 Shared Buffer 里。
Shared Buffer 主要负责以下事情:
(可选)部分算子的状态可能会很小,如 SimpleAgg。根据 local state 的大小,适当地在不同算子的 state 在文件粒度上之间做切分和合并。
将算子本地的状态上传到 shared storage 上。
向 meta service 注册已经成功上传成功的 state 记录。
服务来自算子内部对尚未上传成功的 local state 的查询。
这里的 3 和 4 很好地回答了上一小节提的问题。
从用户的视角,只有一个 epoch 内所有算子的 local state 全部上传完成并在 meta service 注册成功,才认为这个 checkpoint 是完成的,无论是正常 query 还是 recover,都会基于最新的完整 checkpoint。
从内部算子的视角,在读自己 state 的时候,必然是要求读到完整最新状态的,那么事实上内部算子需要的是 remote state + shared buffer + local state merge 后的结果。这里 RisingWave 也提供了 MergeIterator 来做这个泛化。
Local Cache
由于大部分状态在 remote state 中,RisingWave 可以很简单地实现 scale-out,然而带来的代价也是很明显的。相比于 Flink 这种 local state 的设计,RisingWave 需要多很多 remote lookup。
我们以 HashAgg 为例,当 HashAgg 算子收到 Barrier 后,它会把当前 barrier 的统计结果 dump 到 shared buffer,将算子本地的 state 重置为空。然而在处理下一个 epoch 数据的时候,最近处理过的 group key 很可能依然就是热点,我们不得不重新从 shared buffer 甚至 remote state 重新将对应的 key 捞回来。因此我们的选择是,在算子内部不再将之前 epoch 的 local state 重置清空,而是将其标记为 evictable,当且仅当内存不足时,再清理 evictable 的数据记录。
如果我们重新 review 一下整个 state store 的设计的话,就会发现这是一颗基于 cloud 的大 LSM 树。每个算子的 local state 和 shared buffer 对应于 memtable(允许 concurrent write,因为所有 stateful 算子保证了 distribution),而 shared storage 里存储的则是 SSTs,meta service 则是一个中心化的 manifest,作为 source of truth,并且根据元信息触发 compaction 任务。
本文简单介绍了 RisingWave State Store 的基本架构和设计上的 trade off。核心思路是尽可能利用云上 shared storage 的能力,享受 remote state 的优势 – scalability 和更强的弹性扩缩容能力,又希望在 hot state 较小的场景依然能达到 local state 的性能。当然这一切并非毫无代价,而在云原生的架构下,我们可以让这个 trade-off 由用户来选择。
全世界有几千种编程语言,任何一个系统学过编译原理的本科生,都可以设计出自己的 toy language 并实现一个 mini compiler。大部分语言都会设计自己喜欢的语法去表达一些通用的基础设施:基础类型、字符串、变量、条件分支、循环、函数、结构体,这些都是朝三暮四、朝四暮三的区别,也不会成为一个语言本质的创新。 本文不会介绍 Zig 的基础语法,而是想安利一下 Zig 的一个重要 feature —— comptime。
C++ 有非常强大的编译期运算能力,meta programming 的魔法层出不穷,且在每个 C++ 版本越迭代越博大精深,然而对于学习者来说,是非常陡峭的学习曲线。Meta Programming 完全是内置于 C++ 编译器的另一套语法非常复杂、报错非常不友好的函数式编程语言。曾经看到过一个观点(来源请求),如果只是为了在编译期生成足够高效的代码,与其将元编程做得越来越复杂,不如直接引入 Python 作为编译期的胶水语言。那么 Zig 就做出了一个类似的选择:Zig 在编译期引入 Zig 自身作为胶水语言来生成代码,这就是 Zig comptime。
If T is an FFI-safe non-nullable pointer type, Option is guaranteed to have the same layout and ABI as T and is therefore also FFI-safe. As of this writing, this covers &, &mut, and function pointers, all of which can never be null.
我一度把这种成长焦虑误以为这是职级焦虑,毕竟某个scope内最年轻的P7听起来是个很好听的title,也带来了巨大的对保持快速晋升的渴望,看不到合适的机会是令人焦虑的。但我很快就发现这只是表象,在我观察了许多P8,发现他们能做的事情甚至可能还不如我之前作为一个 new grad 在旷视能做的事情多后,我明白这与职级无关,是一种对成长停滞的焦虑,这样的P8也并非是我现在想追求的东西(当然他们的package还是很动人的)。
Evict All:所有算子都被当成 Stateless 的,这种情况下所有的查询都会走 upquery,等于典型的 AP 查询。
Evict None:所有算子都保存 Full State,所有查询都只走叶子节点的 External View。
实际的状态则是多个维度 trade off 过的 Partial State:
访问频率更高、重新计算代价更高、状态存储占用更低的状态更倾向于被保留。
访问频率更低、重新计算代价更低、状态存储占用更搞的状态更倾向于被淘汰。
这种 Partial State 符合大量应用的特征,很多分析往往是更关注头部用户的分析结果,头部用户无论是产出内容还是粉丝数交互数都更多,相同的查询重新计算的代价也高。而应用的不活跃用户往往查询频率很低,且重新从 Base Table 计算代价也很低,用跟头部用户相同的状态(空间、写放大)为他们维护所有 View 是很不划算的事情。Noria 可以全自动地做这个事情。
从这个结果来看,Noria 在开头对自己的定位就非常精准了,它是一个 eventually consistency、near realtime、以及非常易于使用的 Redis 替代品,用户可以像直连数据库一样达到缓存的效果,同时还有更好的缓存语义。
在上面的实现里,我们通过一个 Assert 的 trick,允许我们在 impl 的 block 上为常量参数 S 添加条件判断,而 S 本质上就是一个 bitflags,标识了某一个参数是否被设置过,为此我们仅为 ABuilder<S> where Assert::<{S & 0b110 == 0b110}>: IsTrue 实现 finish 方法,这就满足了我们的需求。
报错大概长这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14
error[E0599]: the method `finish` exists for struct `ABuilder<{S | 0b100}>`, but its trait bounds were not satisfied --> src/lib.rs:70:62 | 4 | enum Assert<const COND: bool> {} | ----------------------------- doesn't satisfy `Assert<{S & 0b110 == 0b110}>: IsTrue` ... 17 | struct ABuilder<const S: u64> { | ----------------------------- method `finish` not found for this ... 70 | let _b = ABuilder::<0>::default().a(0).c(0).finish(); | ^^^^^^ method cannot be called on `ABuilder<{S | 0b100}>` due to unsatisfied trait bounds | = note: the following trait bounds were not satisfied: `Assert<{S & 0b110 == 0b110}>: IsTrue`
只能传递一次的参数
此时我们又对 c 提了一些奇怪需求,我们希望 c 是可选参数,但是最多只会被传递一次(即 0 或 1 次):
上午摸鱼的时候,读了雷宇哥哥的文章 I beat TiDB with 20 LOC,这篇文章非常有意思,推荐 go 吹/go 黑都可以读一读,通过这篇文章,我发现了 cgo 比想象的要快很多,以及 go 编译器比想象更烂,以至于 cgo 的 overhead 完全抵消了还不够。在学习 TiDB 先进经验的时候,看到了一段有意思的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
func(b *builtinArithmeticPlusIntSig) plusSS(result *chunk.Column, lhi64s, rhi64s, resulti64s []int64) error { for i := 0; i < len(lhi64s); i++ { if result.IsNull(i) { continue }
说好的福利(伪):我改完 Plus 就懒得改了,目测 Sub/And/Or/Not/Xor/… 肯定都能提升的,Mul/Div/Mod 可能需要 benchmark 一下才知道有没有提升,同时 TiKV 上也可以水一堆,感兴趣的可以去水一个 PR 薅 TiDB 的 new contributor 周边杯子。有能力的也可以把 non-strict Plus 实现一下(也很 trivial,就是要思考一下用户接口)。
]]><p>标题党,今天给 TiDB 水了个有意思的 PR,随便写个 blog 记录一下。<strong>文末粉丝福利</strong></p>五一摸鱼周记:更新 Blog 主题、水 PRhttps://blog.zhuangty.com/update-blog-theme/2021-05-06T13:09:06.000Z2024-06-10T13:19:55.923Z灌水一篇,这篇文章会介绍:
更新Blog主题的底层逻辑
利用 vercel serverless 赋能 blog 的 slogan
打好 hexo-fluid-theme 和 cusdis 的组合拳
反哺 cusdis 的生态
🐶狗头保命
更新 blog 主题是一个比写 blog 文章快乐多了的事情,这也是 blog 新手常常陷入的一个陷阱 —— 精心配置一整天的主题、评论、评论、插件,然后写下一篇 类似于 Hello World 的《使用XXX 搭建 blog》之后从此吃灰。为了避免自己陷入这个陷阱,我搭 blog 的时候给自己定下了一个规则 —— 每次写一篇文章才能更新一次与文章无关的 blog 配置。
最终的结果是 —— 我既没有保持合适的更新频率,也没机会折腾主题,直接使用了烂大街的 hexo next,没有评论,没有 Analytics,甚至连 Hello World 都没写,创造了一个三无 blog。
直到今年开始,我成功更新了两篇文章(这里非常感谢 Taio App,让我在手机上也能快乐地写 blog),适当地让 blog 更易用一些也提上了日程
个人搭建并维护 blog 还是比较麻烦的事情,一个关键技巧是在掌控数据的前提下尽可能依赖第三方服务。这次的整套组合拳打下来基本也就花了半天的时间在折腾(没有 vercel 可能一天起步了,点赞*3),但数据是以可以掌控的格式(postgresql,可以自己备份)存储的。考虑到 Donald Trump 被封禁到搭建了自己的个人博客,可见 blog 这种去中心化的组织形式还是有必要的。
var ( marshalInfoMap = map[reflect.Type]*marshalInfo{} marshalInfoLock sync.Mutex )
// getMarshalInfo returns the information to marshal a given type of message. // The info it returns may not necessarily initialized. // t is the type of the message (NOT the pointer to it). funcgetMarshalInfo(t reflect.Type) *marshalInfo { marshalInfoLock.Lock() u, ok := marshalInfoMap[t] if !ok { u = &marshalInfo{typ: t} marshalInfoMap[t] = u } marshalInfoLock.Unlock() return u }
funcMarshal(pb Message) ([]byte, error) { if m, ok := pb.(newMarshaler); ok { siz := m.XXX_Size() b := make([]byte, 0, siz) return m.XXX_Marshal(b, false) } if m, ok := pb.(Marshaler); ok { // If the message can marshal itself, let it do it, for compatibility. // NOTE: This is not efficient. return m.Marshal() } // in case somehow we didn't generate the wrapper if pb == nil { returnnil, ErrNil } var info InternalMessageInfo siz := info.Size(pb) b := make([]byte, 0, siz) return info.Marshal(b, pb, false) }
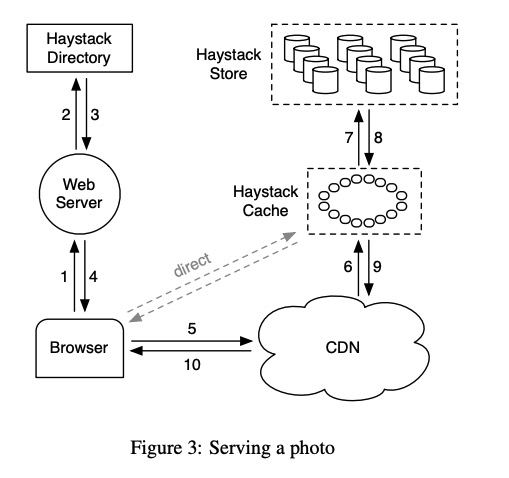
Index file 是定期 dump 到磁盘中的,因此宕机时会丢失数据,需要恢复,对于新写入的数据这非常简单,因为遗失的数据总是在 data file 的尾部,从 index 中最高的 offset 开始从 data file 恢复这些 meta 信息即可。但是对于删除的数据无法简单地恢复,在旧版本的 Haystack(即 Haystack paper)中,删除是通过修改 data file 中 needle 的标志位来完成持久化的,而在新版本(F4 paper 中提到的 Haystack),每次删除文件仅需要在 journal file 中添加一条记录,这是磁盘 append 操作因此非常快,而 Index 在宕机恢复时仅需要将 Journal file 和 Index file 做一个 merge 即可。
/* Macros to use in case the object pointer may be NULL: */ #define Py_XINCREF(op) \ do { \ PyObject *_py_xincref_tmp = (PyObject *)(op); \ if (_py_xincref_tmp != NULL) \ Py_INCREF(_py_xincref_tmp); \ } while (0)
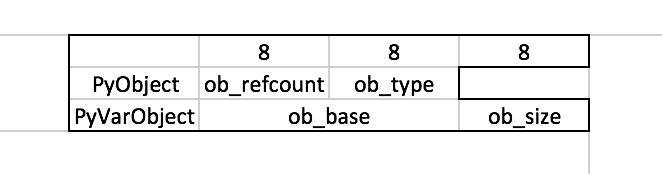
Nothing is actually declared to be a PyObject, but every pointer to a Python object can be cast to a PyObject*. This is inheritance built by hand. Similarly every pointer to a variable-size Python object can, in addition, be cast to PyVarObject*.
typedefstruct _typeobject { PyObject_VAR_HEAD constchar *tp_name; /* For printing, in format "<module>.<name>" */ Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation */
defineVar :: Env -> String -> LispVal -> IOThrowsErrorLispVal defineVar envRef var value = do alreadyDefined <- liftIO $ isBound envRef var if alreadyDefined then setVar envRef var value >> return value else liftIO $ do valueRef <- newIORef value env <- readIORef envRef writeIORef envRef ((var, valueRef) : env) return value
defineVar :: Environment -> String -> SchemeValue -> IOThrowsErrorSchemeValue defineVar envRef varname val = do env <- liftIO $ readIORef envRef liftIO $ do valRef <- newIORef val writeIORef envRef (Map.insert varname valRef env) return val
删去了变量是否存在的判断,一律插入新的 IORef,修复了这个 bug。
命令式语言特性的实现
Haskell 是支持一部分命令式的语法的,所以我实现了 begin 语句 和 while 语句,不过在我的实现方法中很难正确的实现 while 语句,所以我用了一个很 Hack 的实现,在 Parser 的阶段将 while 语句 parse 成 if 语句和 尾递归调用的语法糖,这种实现有很多问题比如栈溢出等,所以其实没有正确实现这个特性。
作为 API 小组,我们的文档非常重要,不过我们组都不是很擅长写文档,这里感谢马子俊同学承包了几乎所有的文档工作,写出了完整的接口文档供其他组的同学使用,并受到了好评。
不过担任 API 小组也让人体会到了甲方的坑爹之处,毕竟别的组的项目都是自己提需求,自己伪装成用户,可以什么好做做什么。起初我组只打算给一到两组提供 API,甚至没有的话完全可以自己搭建客户端来展示,后来在老师的要求下为其他所有组提供相关的 API,不得不说这并不是个愉快的体验,我组面临二十来个甲方提需求不堪重负,甚至相当一部分需求是受限于学校系统无法完成的,虽然让他们自己做他们也完不成,但是要求我们提供的时候丝毫没有觉悟。此外我们原来希望联合的小组开发进度不要太快,这样我们可以比较优雅地组织我们的代码,但部分强力的组加入后我们不得不赶工。出于尽可能让他们能够稳定开发的目的,我组不得不先以功能为第一目的,在安全性、性能等原本很重要的地方做一些让步以适应他们的开发。而且人多口杂需求多,在某些新加入的组的要求下被迫做出一些对已经稳定的 API 修改接口的行为,从某种程度上来说我们拉低了他们的开发进度,他们拉低了我们的代码质量。
]]><p>这学期(又)上了一遍软工3,一开始准备做个微信端的校园服务公众号,后来感觉不是很喜欢微信开发,需要纠结很多微信 API 和权限的问题,所以更换了纯 API 的项目。</p>
<p><a href="https://github.com/TennyZhuang/CamusAPI">CamusAPI</a> 这个项目的初衷是希望建立一个清华内部的校园开放 API 平台,供校园应用的开发者使用,不需要处理复杂的爬虫逻辑和页面逻辑,将学校的系统封装成一层清晰完整的 RESTful API 系统。</p>